Step1. 在Ubuntu上安裝Ctags與Cscope
sudo apt-get install cscope
sudo apt-get install exuberant-ctags
Step2. 在Sublime Text上安裝Ctags與Cscope套件
(1) 先安裝Package Control:選取「View -> Show Console」,貼上「https://packagecontrol.io/installation」網址中的指令按enter安裝
(2) 選取「Preference -> Package Control」,打i後選install package按enter,打ctags按enter安裝
(3) 選取「Preference -> Package Control」,打i後選install package按enter,打cscope按enter安裝
2015年11月10日 星期二
2015年1月16日 星期五
[機器學習] 降維演算法:主成分分析(Principal Component Analysis, PCA)
以下講解如何公式化主成分分析演算法,假設我有如下二維data,我們想要將它投影到一條直線上使其降成一維,那麼該如何找出最佳的一條直線來投影呢?
PCA要做的就是找出一個低維度的投影平面(在這個例子是一條紅色直線),當我們將data投影到上面,data與這條線之間的平方投影誤差(squared projection error)能夠最小化。平方投影誤差就是data「原始的」位置與「投影到平面上後」的位置之間距離的「平方」。
正式定義:
當你想將二維資料降成一維時,PCA會尋找一個對資料進行投影的方向,或稱一個向量${ u }^{ (i) }\in { R }^{ n }$,在這邊就是${ u }^{ (i) }\in { R }^{ 2 }$,使得投影誤差能夠最小化。這個向量是正是負都沒關係,因為即使是相反方向,定義出的直線(投影方向)還是一樣的。
以此類推,如果要將n維資料降成k維時,我們就要找出k個方向(向量)來將data投影到由這k個向量所形成的一個k維平面上。

以右圖為例,假設我要將三維降成兩維,現在k=2,則我們要找出從原點延伸出來的兩個方向(向量):${ u }^{ (1) }$與${ u }^{ (2) }$,這兩個向量會定義一個二維平面,我們就可以將data投影到這個平面上。
用線性代數的術語來說,就是要將data投影到這k個向量生成的線性子空間中。
那麼PCA跟線性回歸有什麼關係呢?看起來很像但兩者意義不太一樣,線性回歸要最小化的東西是每個點與回歸直線之間的平方誤差,是一個垂直距離,它是某個點與透過假設所得到的其預測值y之間的距離。而PCA要最小化的東西是每個點與直線之間的直角距離(orthogonal distance)。

線性回歸做的是用x中所有的值來預測一個特殊變數y,但在PCA沒有這麼一個要預測的y,我們擁有的就是一群特徵${ x }_{ 1 },{ x }_{ 2 }, ... , { x }_{ n }$,這些特徵都是被同等對待的,沒有所謂的特殊變數y需要被預測。
因此,如果我要將三維降成兩維,我要做的就是找出兩個方向,並將data投影到二維平面上,此時三個特徵${ x }_{ 1 }$、${ x }_{ 2 }$與${ x }_{ 3 }$是被同等對待的。
問題:















PCA要做的就是找出一個低維度的投影平面(在這個例子是一條紅色直線),當我們將data投影到上面,data與這條線之間的平方投影誤差(squared projection error)能夠最小化。平方投影誤差就是data「原始的」位置與「投影到平面上後」的位置之間距離的「平方」。
正式定義:
當你想將二維資料降成一維時,PCA會尋找一個對資料進行投影的方向,或稱一個向量${ u }^{ (i) }\in { R }^{ n }$,在這邊就是${ u }^{ (i) }\in { R }^{ 2 }$,使得投影誤差能夠最小化。這個向量是正是負都沒關係,因為即使是相反方向,定義出的直線(投影方向)還是一樣的。
以此類推,如果要將n維資料降成k維時,我們就要找出k個方向(向量)來將data投影到由這k個向量所形成的一個k維平面上。

以右圖為例,假設我要將三維降成兩維,現在k=2,則我們要找出從原點延伸出來的兩個方向(向量):${ u }^{ (1) }$與${ u }^{ (2) }$,這兩個向量會定義一個二維平面,我們就可以將data投影到這個平面上。
用線性代數的術語來說,就是要將data投影到這k個向量生成的線性子空間中。
那麼PCA跟線性回歸有什麼關係呢?看起來很像但兩者意義不太一樣,線性回歸要最小化的東西是每個點與回歸直線之間的平方誤差,是一個垂直距離,它是某個點與透過假設所得到的其預測值y之間的距離。而PCA要最小化的東西是每個點與直線之間的直角距離(orthogonal distance)。

線性回歸做的是用x中所有的值來預測一個特殊變數y,但在PCA沒有這麼一個要預測的y,我們擁有的就是一群特徵${ x }_{ 1 },{ x }_{ 2 }, ... , { x }_{ n }$,這些特徵都是被同等對待的,沒有所謂的特殊變數y需要被預測。
因此,如果我要將三維降成兩維,我要做的就是找出兩個方向,並將data投影到二維平面上,此時三個特徵${ x }_{ 1 }$、${ x }_{ 2 }$與${ x }_{ 3 }$是被同等對待的。
問題:

主成分分析演算法
在使用PCA之前,我們習慣先做mean normalization以及feature scaling。mean normalization是一定要做的,feature scaling則視data set而定,我們先計算每個特徵的平均${ u }_{ j }$,並將每個特徵${ x }_{ j }^{ (i) }$用${ x }_{ j }-{ u }_{ j }$取代,如果每個特徵值範圍差太多,我們再用特徵縮放來處理。${ S }_{ j }代表最大值減最小值。
現在問題就是,該如何找到我們要的${ u }^{ (1) }$、${ u }^{ (2) }$、${ z }_{ 1 }$與${ z }_{ 2 }$等等呢?

以數學角度來說,我們要先計算一個covariance矩陣,它的符號與「求和」符號一樣,在這邊不要搞混就好,我們會將它存在一個Sigma變數中,接下來就是要求它的eigenvectors,將svd()方法用於這個covariance矩陣會得到三個矩陣U,S,V。U矩陣為一個n*n矩陣,如果想要將矩陣降到k維,我們就只要取U矩陣的前k個行向量,這k個向量就是我們要找的k個方向,將data投影到上面。

如果要將我們原始的data set $x\in { R }^{ n }$用一個低維度的$z\in { R }^{ k }$表示,就是取U矩陣的前k個向量,取出來後把這個n*k矩陣叫做${ U }_{ reduce }$。而z就是這個矩陣的轉置乘上x,z是一個k*n矩陣,而x是一個n*1向量,最後會得出一個k*1向量,還算合理。如果要針對某個training example ${ x }^{ (i) }$,我們就在x上面加個上標i即可,最後會得出${ z }^{ (i) }$。

總結,右邊的計算方式是一種向量化寫法,在octave中「'」代表「T」:

問題:

主成分元素的個數
當我們要將資料從n維降成k維時,k是一個PCA演算法要輸入的變數,這個k又叫作「主成分元素的個數」,以下講解該如何找出這個k。
首先,PCA在做的就是要最小化平均平方投影誤差。另外,我們的data的總變異就是所有樣本長度的平均。

只要這個k能夠使得這兩者相除小於0.01,找出當中最小的k即可。當別人問你留下了多少主成分,你可以說你選擇了一個k,代表留下了k個主成分,這個k保留了99%的variance。0.01是大家最常用的數值,0.05也可以,最常見就是k保留了95%~99%的variance。
再來,該怎麼選k呢?你可以從k=1開始一直算,直到該式子小於等於0.01為止。很明顯這不太有效率,我們可以換個方式,用svd分解來找,取出svd分解後的Sigma矩陣,給定一個k,我們只要算出1減掉這k個對角線的值的總和除以n個對角線的值的總和是否小於等於0.01即可。換個角度講就是,這k個對角線的值的總和除以n個對角線的值的總和要大於等於0.99。

因此,你只要慢慢增加k就好,而且只要呼叫一次SVD即可。
總結:

重建資料(Reconstruction)
以下面例子來說,我們該如何將$z\in { R }$轉回$x\in { R }^{2}$呢?由於$z={ U }_{ reduce }^{T}x$,要重建成原本的資料只要求${ x }_{ approx }={ U }_{ reduce }z$即可,但是只能重建成近似資料,沒辦法一模一樣。

問題:假設我們要進行降維,但是是降成k=n維(也就是一模一樣維度),以下何者算正確?

假設你有個100*100=10000pixels的影像資料,你的特徵向量{x}^{(i)}就會包含10000個pixels的亮度值,也就是特徵向量為10000維。想像一下如果將這個10000維的特徵向量丟給監督學習演算法,例如邏輯回歸、神經網路或是支援向量機,這速度想必會非常慢,此時用PCA壓縮一下資料可以加快演算法的速度。
首先我們先取出data set中的input部分,也就是特徵向量x,這還是10000維。此時對它做PCA後,可能可以得到一個低維度(或許1000維)的特徵向量z,這樣我們將會得到一個新的data set,這個新的data set,input部分已經變成了z。

錯誤的PCA用法:使用PCA來降低特徵數量以防止over-fitting

正確的用法:使用regularization來防止over-fitting
最後,在使用PCA以前,你應該確保演算法在原始數據上進行過嘗試,只有在這種嘗試達不到你預期結果時才採用PCA。因為大部分人在做project時會加入「將資料進行壓縮」這個步驟,而其實不用壓縮似乎也不影響結果。

[機器學習] 將高維度資料壓縮(Data Compression)與視覺化(Visualization)
資料壓縮
為何要將資料壓縮?主要有兩大好處:
- 減少硬碟與記憶體空間的使用
- 加快演算法速度
如果我們現在有個data set具有非常非常多特徵,例如50個特徵,我們隨便取兩個特徵出來,假設特徵${ x }_{ 1 }$是某樣東西用公分表示的長度,特徵${ x }_{ 2 }$是同樣東西用英寸表示的長度。
明明是針對同一樣東西,卻用兩個特徵來表示它的長度,看似有一個特徵是多餘的。因此,我們可以嘗試將data set從二維轉到一維,看能不能只用一個特徵值來代表這樣東西的長度就好。
現在,假設我們有如下圖二維的data set,想將它們降到一維,我們可以將這些data投影(projection)到那條綠色的回歸線上,投影後我們要做的就只是測量每個data在這條直線上的位置,透過建立一個新的特徵假設叫做${ z }_{ 1 }$,只需要一個值就可以記錄每個data在這條線上的位置了。

因此,過去每一個樣本都要用兩個值來表示,現在只要用一個值就可以了。經過降維,我用來儲存資料的硬碟或記憶體空間可能就只有過去的一半而已,但更有感的可能是加快演算法的速度。
同樣的,我們也可以將三維的資料降成二維,而在實際操作上,你還可能會遇到要將1000維的資料降成100維這種例子。

左圖中,你可以發現這群data約略是圍繞在一個平面周圍的感覺,我們試著將這些data投影到一個二維平面,如中間那個圖,投影後,所有data都在一個二維平面上了,所以我們要用兩個值來表示每一個data對吧?
這兩個值分別就是用圖中兩條綠色軸${ z }_{ 1 }$與${ z }_{ 2 }$上的值來表示,將這兩個軸獨立出來後,就變成了右圖,用${ z }_{ 1 }$軸與${ z }_{ 2 }$軸來表示這些data。
以下分別為上圖中對應的圖,第一張圖為data在三維空間時的散佈樣子,第二張圖則是將這些三維data投影到一個二維平面時的樣子,知道這個二維平面的兩個軸${ z }_{ 1 }$與${ z }_{ 2 }$後,第三張圖就是以${ z }_{ 1 }$與${ z }_{ 2 }$來表示這些data的位置。



視覺化
現在,假設我們有一些國家的資料作為它們的特徵,假設有50個特徵好了,我們要怎麼視覺化這50維的data呢?首先,辦不到,與其用一個50維的特徵向量${ x }^{ (i) }$表示每一個國家,不如嘗試用一個二維的特徵向量來表示,也就是使用之前所說的兩個特徵${ z }_{ 1 }$與${ z }_{ 2 }$來表示,而這就要用到降維了。要注意的是,降維後的結果只能粗略代表這50個特徵,也就是結果多少會與原始資料有些許出入。


我們將上表畫出來,${ z }_{ 1 }$軸與${ z }_{ 2 }$軸可能就各代表一群特徵的綜合值。

勘誤:上圖左下角應該是${ z }^{ (i) }\in { R }^{ 2 }$
2015年1月14日 星期三
[機器學習](十)向量化(Vectorization):低維度矩陣分解(Low Rank Matrix Factorization)
向量化的意思就是把一些for迴圈的操作轉換成矩陣的操作,速度會比寫一般迴圈快非常多。比如說線性回歸,求預測值時,普通做法是一個樣本求一次,而m個樣本就要用for迴圈求m次,向量化操作就是用矩陣相乘的方式,一次求出m個樣本的預測值。
以協同過濾的例子為例,之前我們說使用者j對電影i的預測評分為${({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$,現在,我們該如何使用向量化的方式來預測評分呢?
首先,先寫出參數向量$\Theta$與特徵向量X,此時為了計算所有預測矩陣中的評分,只要將${ \Theta }^{ T }$與X這兩者相乘即可,這種向量化式的做法又叫作Low Rank Matrix Factorization。

除了跑此演算法外,還有其他可以做的事,也就是使用學習到的特徵向量來找出相關電影。
例如,如果你發現電影i的特徵向量與電影j的特徵向量,彼此之間的距離很相近,代表兩者可能很類似,則使用者喜歡電影i或許也會喜歡電影j。
假設你現在有五部電影j,其都與電影i有關,則你可以計算這五部電影各自的特徵向量與電影i的特徵向量之間的距離,最小者就是最相似者,而這可以讓你推薦給使用者比較不同的電影。
使用Mean Normalization加強協同過濾演算法:

如果現在多了一個使用者Eve,其對任何電影都沒有評分過,來看看協同過濾怎麼處理它。
假設現在n=2,代表有兩個特徵,我們要求Eve的${ \Theta }^{ (5) }$。由於Eve沒有評過任何電影,也就是沒有任何r(i,j)=1,導致會影響${ \Theta }^{ (5) }$的就只有式子最後的那一個正規項目。
如果你的目標是要最小化這個正規項目,則只要將${ \Theta }^{ (5) }$設$\begin{bmatrix} 0 \\ 0 \end{bmatrix}$就好。
因為正規項目鼓勵我們將參數設定成儘量接近0。因此,${({ \Theta }^{ (5) }) }^{ T }{ x }^{ (i) }=0$,將會預測Eve對所有電影的評分都是0。這看起來好像沒什麼用,因為有些電影有些人還是有評分,而這也讓我們很難推薦Eve某部電影,因為每個Eve對電影的預測評分都是0,都是一樣的,沒有比較高分的電影可以讓我們推薦。
因此,Mean Normalization的做法就是讓我們解決這個問題。
首先,我們計算出每部電影的平均得分,將其記在向量$\mu $中,再來,將原矩陣的每一列減掉平均值,現在每部電影在這個Y矩陣中都有一個0的平均評分(average rating of zero?)。

此時,假設這個Mean Normalize movie rating矩陣中的評分確實是從使用者那邊得到的評分,我將使用這個矩陣來學習參數向量${ \Theta }^{ (j) }$以及特徵向量${ x }^{ (i) }$。
對於使用者j,預測其對電影i的評分,最後要加回去減掉的${ \mu }_{ i }$:
${({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }+{ \mu }_{ i }$
這是很合理的,因為我們根本不知道新使用者的喜好,所能做的就是對於該使用者,預測其給予電影的評分值可能是該電影的平均的得分值。
最後,一般狀況下,「某個使用者還未對任何電影評過分」,其重要程度可能會比「某個電影還未得到任何一個評分」來得高。
問題:

以協同過濾的例子為例,之前我們說使用者j對電影i的預測評分為${({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$,現在,我們該如何使用向量化的方式來預測評分呢?
首先,先寫出參數向量$\Theta$與特徵向量X,此時為了計算所有預測矩陣中的評分,只要將${ \Theta }^{ T }$與X這兩者相乘即可,這種向量化式的做法又叫作Low Rank Matrix Factorization。

除了跑此演算法外,還有其他可以做的事,也就是使用學習到的特徵向量來找出相關電影。
例如,如果你發現電影i的特徵向量與電影j的特徵向量,彼此之間的距離很相近,代表兩者可能很類似,則使用者喜歡電影i或許也會喜歡電影j。
假設你現在有五部電影j,其都與電影i有關,則你可以計算這五部電影各自的特徵向量與電影i的特徵向量之間的距離,最小者就是最相似者,而這可以讓你推薦給使用者比較不同的電影。
使用Mean Normalization加強協同過濾演算法:

如果現在多了一個使用者Eve,其對任何電影都沒有評分過,來看看協同過濾怎麼處理它。
假設現在n=2,代表有兩個特徵,我們要求Eve的${ \Theta }^{ (5) }$。由於Eve沒有評過任何電影,也就是沒有任何r(i,j)=1,導致會影響${ \Theta }^{ (5) }$的就只有式子最後的那一個正規項目。
如果你的目標是要最小化這個正規項目,則只要將${ \Theta }^{ (5) }$設$\begin{bmatrix} 0 \\ 0 \end{bmatrix}$就好。
因為正規項目鼓勵我們將參數設定成儘量接近0。因此,${({ \Theta }^{ (5) }) }^{ T }{ x }^{ (i) }=0$,將會預測Eve對所有電影的評分都是0。這看起來好像沒什麼用,因為有些電影有些人還是有評分,而這也讓我們很難推薦Eve某部電影,因為每個Eve對電影的預測評分都是0,都是一樣的,沒有比較高分的電影可以讓我們推薦。
因此,Mean Normalization的做法就是讓我們解決這個問題。
首先,我們計算出每部電影的平均得分,將其記在向量$\mu $中,再來,將原矩陣的每一列減掉平均值,現在每部電影在這個Y矩陣中都有一個0的平均評分(average rating of zero?)。

此時,假設這個Mean Normalize movie rating矩陣中的評分確實是從使用者那邊得到的評分,我將使用這個矩陣來學習參數向量${ \Theta }^{ (j) }$以及特徵向量${ x }^{ (i) }$。
對於使用者j,預測其對電影i的評分,最後要加回去減掉的${ \mu }_{ i }$:
${({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }+{ \mu }_{ i }$
這是很合理的,因為我們根本不知道新使用者的喜好,所能做的就是對於該使用者,預測其給予電影的評分值可能是該電影的平均的得分值。
最後,一般狀況下,「某個使用者還未對任何電影評過分」,其重要程度可能會比「某個電影還未得到任何一個評分」來得高。
問題:

[機器學習](九)基於協同過濾之推薦系統(Collaboorative Filtering)
假設我們現在不知道${ x }_{ 1 }$與${ x }_{ 2 }$這兩個特徵的指數,而是依靠使用者的「參數向量$\Theta$」,也就是使用者所給予的喜好程度,來判斷特徵向量中的值。

現在我們要求電影1的特徵向量${ x }^{ (1) }$,假設已經事先知道${ \Theta }^{ (1) }$到${ \Theta }^{ (4) }$,且也已經約略知道各使用者對每部電影的評分:
使用者1對電影1的評分:${ ({ \Theta }^{ (1) }) }^{ T }{ x }^{ (1) }\approx5$
使用者2對電影1的評分:${ ({ \Theta }^{ (2) }) }^{ T }{ x }^{ (1) }\approx5$
使用者3對電影1的評分:${ ({ \Theta }^{ (3) }) }^{ T }{ x }^{ (1) }\approx0$
使用者4對電影1的評分:${ ({ \Theta }^{ (4) }) }^{ T }{ x }^{ (1) }\approx0$
則可以得知${ x }^{ (1) }=\begin{bmatrix} 1 \\ 1.0 \\ 0.0 \end{bmatrix}$


因此,現在的最佳化演算法與之前的相反過來,之前是假設先有電影的特徵向量,我們要去學習使用者的參數向量,現在是假設先有使用者的參數向量,我們要去學習電影的特徵向量
這就像是雞生蛋還是蛋生雞的問題,我們有使用者的參數向量可以學習電影的特徵向量,我們有電影的特徵向量,也可以學習使用者的參數向量。

因此,所要做的就是先隨機猜一個$\Theta$值,學習到不同電影的特徵後,基於這些特徵,又可以去學習一個更好的$\Theta$值,再利用這個$\Theta$值去學習特徵,如此重複計算,不斷迭代優化下去,最後會收斂到一組合理的電影的特徵以及一組合理的對使用者參數的估計。
因此協同過濾換句話說就是每位使用者都藉由評分來幫助演算法更好地學習出特徵,透過自己對幾部電影評分後,就能幫助系統更好地學習。
但是,其實有一個演算法讓我們不用一直重複計算$\Theta$和X,其可以直接同時將$\Theta$和X算出來,也就是將兩者結合在一起。

之前是先最小化$\Theta$,再最小化X,再最小化$\Theta$,再最小化X,如此重複下去。
在新的式子中,會將這兩者同時化簡。
然而原本固有的假設${ x }_{ 0 }=1$必須去掉,所以這些我們將學習的特徵向量X將會是n維實數,而非之前的n+1維實數,同理參數向量$\Theta$也會是n維實數,因為${ \theta }_{ 0 }$也不存在了。
因為我們現在正在自動學習所要使用的所有特徵,所以不需要將這個等於1的特徵值${ x }_{ 0 }$固定住,如果演算法真的要將它固定成1,它會自己去做,不用我們手動。

總結,如果使用者j還沒對電影i評過分,就是用${({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$來算出預測的評分。
題目:


現在我們要求電影1的特徵向量${ x }^{ (1) }$,假設已經事先知道${ \Theta }^{ (1) }$到${ \Theta }^{ (4) }$,且也已經約略知道各使用者對每部電影的評分:
使用者1對電影1的評分:${ ({ \Theta }^{ (1) }) }^{ T }{ x }^{ (1) }\approx5$
使用者2對電影1的評分:${ ({ \Theta }^{ (2) }) }^{ T }{ x }^{ (1) }\approx5$
使用者3對電影1的評分:${ ({ \Theta }^{ (3) }) }^{ T }{ x }^{ (1) }\approx0$
使用者4對電影1的評分:${ ({ \Theta }^{ (4) }) }^{ T }{ x }^{ (1) }\approx0$
則可以得知${ x }^{ (1) }=\begin{bmatrix} 1 \\ 1.0 \\ 0.0 \end{bmatrix}$

問題:

因此,現在的最佳化演算法與之前的相反過來,之前是假設先有電影的特徵向量,我們要去學習使用者的參數向量,現在是假設先有使用者的參數向量,我們要去學習電影的特徵向量
這就像是雞生蛋還是蛋生雞的問題,我們有使用者的參數向量可以學習電影的特徵向量,我們有電影的特徵向量,也可以學習使用者的參數向量。

因此,所要做的就是先隨機猜一個$\Theta$值,學習到不同電影的特徵後,基於這些特徵,又可以去學習一個更好的$\Theta$值,再利用這個$\Theta$值去學習特徵,如此重複計算,不斷迭代優化下去,最後會收斂到一組合理的電影的特徵以及一組合理的對使用者參數的估計。
因此協同過濾換句話說就是每位使用者都藉由評分來幫助演算法更好地學習出特徵,透過自己對幾部電影評分後,就能幫助系統更好地學習。
但是,其實有一個演算法讓我們不用一直重複計算$\Theta$和X,其可以直接同時將$\Theta$和X算出來,也就是將兩者結合在一起。

之前是先最小化$\Theta$,再最小化X,再最小化$\Theta$,再最小化X,如此重複下去。
在新的式子中,會將這兩者同時化簡。
然而原本固有的假設${ x }_{ 0 }=1$必須去掉,所以這些我們將學習的特徵向量X將會是n維實數,而非之前的n+1維實數,同理參數向量$\Theta$也會是n維實數,因為${ \theta }_{ 0 }$也不存在了。
因為我們現在正在自動學習所要使用的所有特徵,所以不需要將這個等於1的特徵值${ x }_{ 0 }$固定住,如果演算法真的要將它固定成1,它會自己去做,不用我們手動。

總結,如果使用者j還沒對電影i評過分,就是用${({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$來算出預測的評分。
題目:

[機器學習](八)基於內容之推薦系統(Content Based Recommendations)
直接舉例:

這裡給出一些定義:
${ n }_{ u }$代表使用者數量
${ n }_{ m }$代表電影數量
r(i,j)代表使用者j是否有對電影i評過分,有則為1,沒有則為0
若使用者j有對電影i評過分,則${ y }^{ (i,j) }$代表使用者j對電影i的評分(0~5顆星)
所以,基於內容之推薦系統的目的就是根據以上資訊,來推測出那些沒有被某使用者評過分的電影可能會是幾分,並將它推薦給那個使用者。
基於內容之推薦:

這邊假設有額外兩個變數:
${ x }_{ 1 }$:負責計算此電影的浪漫指數。
${ x }_{ 2 }$:負責計算此電影的動作指數。
對於每部電影的特徵我們可以把它寫成一個特徵向量。例如電影1有兩個特徵${ x }_{ 1 }$與${ x }_{ 2 }$,以及總是會加上的${ x }_{ 0 }$=1:
其特徵向量${ x }^{ (1) }=\begin{bmatrix} 1 \\ 0.9 \\ 0 \end{bmatrix}$,以此類推。
為了做預測,我們可以將「對使用者評分的預測」看作是獨立的線性回歸問題。我們可以針對每個使用者j去學習一個參數向量${ \Theta }^{ ( j ) }\in { R }^{ 3 }$,其中${ R }^{ ( n+1 ) }$,n為特徵數目。再來,就是預測使用者j會對電影i評${ ({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$分,這就是使用者的參數向量${ \Theta }^{ (j) }$與電影的特徵向量${ x }^{ (i) }$之間的內積。
首先,我們想預測Alice會對其還沒評過分的電影3評幾分,則我們有:
Alice的參數向量(假設的):${ \Theta }^{ (1) }=\begin{bmatrix} 0 \\ 5 \\ 0 \end{bmatrix}$
電影3的特徵向量:${ x }^{ (3) }=\begin{bmatrix} 1 \\ 0.99 \\ 0 \end{bmatrix}$
則對於電影3,我們預測Alice可能的評分為:${ ({ \Theta }^{ (1) }) }^{ T }{ x }^{ (3) }=5 * 0.99=4.95$
因此,針對使用者j,其對電影i,我們所預測的評分為${ ({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$分。
假設現在又有一個變數${ m }^{ (j) }$代表被使用者j評分過的電影數量,則為了學習${ \Theta }^{ ( j ) }$,這又是個線性回歸與正規化的問題,也就是:
$\underset { { \Theta }^{ (j) } }{ min } \frac { 1 }{ 2{ m }^{ (j) } } \sum _{ i:r(i,j)=1 }^{ }{ { ({ ({ \Theta }^{ (j) }) }^{ T }({ x }^{ (i) })-{ y }^{ (i,j) }) }^{ 2 } } +\frac { \lambda }{ 2{ m }^{ (j) } } \sum _{ k=1 }^{ n }{ { ({ \Theta }_{ k }^{ (j) }) }^{ 2 } }$
在推薦系統中,我們要簡化這個式子,丟掉${ m }^{ (j) }$這個常數,結果應該還會是一樣,也就是:
$\underset { { \Theta }^{ (j) } }{ min } \frac { 1 }{ 2 } \sum _{ i:r(i,j)=1 }^{ }{ { ({ ({ \Theta }^{ (j) }) }^{ T }({ x }^{ (i) })-{ y }^{ (i,j) }) }^{ 2 } } +\frac { \lambda }{ 2 } \sum _{ k=1 }^{ n }{ { ({ \Theta }_{ k }^{ (j) }) }^{ 2 } }$
以上是針對單一使用者j的${ \Theta }^{ ( j ) }$,然而推薦系統是要學習所有使用者的$\Theta$,也就是:
$\underset { { \Theta }^{ (1) },...,{ \Theta }^{ ({ n }_{ u }) } }{ min } \frac { 1 }{ 2 } \sum _{ j=1 }^{ { n }_{ u } }{ \sum _{ i:r(i,j)=1 }^{ }{ { ({ ({ \Theta }^{ (j) }) }^{ T }({ x }^{ (i) })-{ y }^{ (i,j) }) }^{ 2 } } } +\frac { \lambda }{ 2 } \sum _{ j=1 }^{ { n }_{ u } }{ \sum _{ k=1 }^{ n }{ { ({ \Theta }_{ k }^{ (j) }) }^{ 2 } } } $
這樣就可以得到屬於每個使用者的參數向量${ \Theta }^{ (1) }$到${ \Theta }^{ ({ n }_{ u }) }$。
這個最佳化演算法我們叫它$J({ \Theta }^{ (1) }, ... ,{ \Theta }^{ ({ n }_{ u }) })$,並搭配梯度下降法來更新${ \Theta }_{ k }^{ (j) }$。

以上就是基於內容之推薦系統的眼算法,因為我們假設我們擁有每部電影的一些特徵,例如這部電影浪漫指數為多少,動作指數為多少等等,藉由這些特徵來判斷每部電影的內容偏向何種類型,並藉此判斷該如何推薦。
但對於許多電影我們並沒有這些特徵,因為這些特徵必須依靠別人看完電影後告訴你每部電影有多浪漫或是多動作,這很困難且耗時,而且你不只會希望擁有浪漫與動作這兩種特徵的指數而已,你還會想要更多特徵的指數,而你該怎樣得到這些特徵?
因此,下一節我們將要討論不是基於內容的推薦系統,其不需要依靠電影的特徵,就可以判斷該如何推薦,也就是基於「協同過濾」之推薦系統。

這裡給出一些定義:
${ n }_{ u }$代表使用者數量
${ n }_{ m }$代表電影數量
r(i,j)代表使用者j是否有對電影i評過分,有則為1,沒有則為0
若使用者j有對電影i評過分,則${ y }^{ (i,j) }$代表使用者j對電影i的評分(0~5顆星)
所以,基於內容之推薦系統的目的就是根據以上資訊,來推測出那些沒有被某使用者評過分的電影可能會是幾分,並將它推薦給那個使用者。
基於內容之推薦:

這邊假設有額外兩個變數:
${ x }_{ 1 }$:負責計算此電影的浪漫指數。
${ x }_{ 2 }$:負責計算此電影的動作指數。
對於每部電影的特徵我們可以把它寫成一個特徵向量。例如電影1有兩個特徵${ x }_{ 1 }$與${ x }_{ 2 }$,以及總是會加上的${ x }_{ 0 }$=1:
其特徵向量${ x }^{ (1) }=\begin{bmatrix} 1 \\ 0.9 \\ 0 \end{bmatrix}$,以此類推。
為了做預測,我們可以將「對使用者評分的預測」看作是獨立的線性回歸問題。我們可以針對每個使用者j去學習一個參數向量${ \Theta }^{ ( j ) }\in { R }^{ 3 }$,其中${ R }^{ ( n+1 ) }$,n為特徵數目。再來,就是預測使用者j會對電影i評${ ({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$分,這就是使用者的參數向量${ \Theta }^{ (j) }$與電影的特徵向量${ x }^{ (i) }$之間的內積。
首先,我們想預測Alice會對其還沒評過分的電影3評幾分,則我們有:
Alice的參數向量(假設的):${ \Theta }^{ (1) }=\begin{bmatrix} 0 \\ 5 \\ 0 \end{bmatrix}$
電影3的特徵向量:${ x }^{ (3) }=\begin{bmatrix} 1 \\ 0.99 \\ 0 \end{bmatrix}$
則對於電影3,我們預測Alice可能的評分為:${ ({ \Theta }^{ (1) }) }^{ T }{ x }^{ (3) }=5 * 0.99=4.95$
因此,針對使用者j,其對電影i,我們所預測的評分為${ ({ \Theta }^{ (j) }) }^{ T }{ x }^{ (i) }$分。
假設現在又有一個變數${ m }^{ (j) }$代表被使用者j評分過的電影數量,則為了學習${ \Theta }^{ ( j ) }$,這又是個線性回歸與正規化的問題,也就是:
$\underset { { \Theta }^{ (j) } }{ min } \frac { 1 }{ 2{ m }^{ (j) } } \sum _{ i:r(i,j)=1 }^{ }{ { ({ ({ \Theta }^{ (j) }) }^{ T }({ x }^{ (i) })-{ y }^{ (i,j) }) }^{ 2 } } +\frac { \lambda }{ 2{ m }^{ (j) } } \sum _{ k=1 }^{ n }{ { ({ \Theta }_{ k }^{ (j) }) }^{ 2 } }$
在推薦系統中,我們要簡化這個式子,丟掉${ m }^{ (j) }$這個常數,結果應該還會是一樣,也就是:
$\underset { { \Theta }^{ (j) } }{ min } \frac { 1 }{ 2 } \sum _{ i:r(i,j)=1 }^{ }{ { ({ ({ \Theta }^{ (j) }) }^{ T }({ x }^{ (i) })-{ y }^{ (i,j) }) }^{ 2 } } +\frac { \lambda }{ 2 } \sum _{ k=1 }^{ n }{ { ({ \Theta }_{ k }^{ (j) }) }^{ 2 } }$
以上是針對單一使用者j的${ \Theta }^{ ( j ) }$,然而推薦系統是要學習所有使用者的$\Theta$,也就是:
$\underset { { \Theta }^{ (1) },...,{ \Theta }^{ ({ n }_{ u }) } }{ min } \frac { 1 }{ 2 } \sum _{ j=1 }^{ { n }_{ u } }{ \sum _{ i:r(i,j)=1 }^{ }{ { ({ ({ \Theta }^{ (j) }) }^{ T }({ x }^{ (i) })-{ y }^{ (i,j) }) }^{ 2 } } } +\frac { \lambda }{ 2 } \sum _{ j=1 }^{ { n }_{ u } }{ \sum _{ k=1 }^{ n }{ { ({ \Theta }_{ k }^{ (j) }) }^{ 2 } } } $
這樣就可以得到屬於每個使用者的參數向量${ \Theta }^{ (1) }$到${ \Theta }^{ ({ n }_{ u }) }$。
這個最佳化演算法我們叫它$J({ \Theta }^{ (1) }, ... ,{ \Theta }^{ ({ n }_{ u }) })$,並搭配梯度下降法來更新${ \Theta }_{ k }^{ (j) }$。

以上就是基於內容之推薦系統的眼算法,因為我們假設我們擁有每部電影的一些特徵,例如這部電影浪漫指數為多少,動作指數為多少等等,藉由這些特徵來判斷每部電影的內容偏向何種類型,並藉此判斷該如何推薦。
但對於許多電影我們並沒有這些特徵,因為這些特徵必須依靠別人看完電影後告訴你每部電影有多浪漫或是多動作,這很困難且耗時,而且你不只會希望擁有浪漫與動作這兩種特徵的指數而已,你還會想要更多特徵的指數,而你該怎樣得到這些特徵?
因此,下一節我們將要討論不是基於內容的推薦系統,其不需要依靠電影的特徵,就可以判斷該如何推薦,也就是基於「協同過濾」之推薦系統。
2015年1月13日 星期二
[機器學習](七)邏輯回歸(Logistic regression)
分類問題
談到二元分類問題(Binary Classification problem),我們可能有以下例子:
郵件:是垃圾還是非垃圾?
腫瘤:是惡性還是良性?
線上交易:是不是詐欺?
在這裡我們要預測的結果y只有兩種值:{0, 1},其中0是負面的(negative class),1是正面的(positive class)。然而multi-class problem的y可能有很多種:{0, 1, 2, 3, ..}
當使用Linear regression演算法時,我們的假設函數為:${ h }_{ \theta }(x)$ = ${ \theta }^{ T }x$

如果將Linear regression演算法運用在這個data set上,得到的hypothesis ${ h }_{ \theta }(x)$ = ${ \theta }^{ T }x$所對應的一條回歸線可能看起來會如圖1.a所示。
如果你想 進行預測,你可能會定義一個分類的門檻值(Threshold classifier output),例如${ h }_{ \theta }(x) = 0.5$(垂直軸)。如果hypothesis輸出的值大於等於0.5,就預測y=1,否則預測y=0。
給定上圖這種data set的狀況下,把Linear regression拿來用在分類問題可能沒什麼問題,但是如果多加了一個training example,如圖1.b,則此條回歸線可能會改變,使得預測結果明顯不準確。因此,把Linear regression用在分類問題時,可能不是個好方法。
因為二元分類問題的輸出結果y只會是1或0,如果把Linear regression用在分類問題,Linear regression輸出的${ h }_{ \theta }(x)$可能會大於1或是小於0,所以接下來的邏輯回歸(Logistic regression),其特性就是它的輸出(預測)永遠都會介在0和1之間,不會有大於1或小於0的情況,也就是0$\le{ h }_{ \theta }(x)\le$ 1, 雖然邏輯回歸演算法有「回歸」這兩個字,但是它其實是被用在分類問題。總之,線性回歸用在分類問題不是個好方法!
簡單說,就是以線性回歸為基礎,在最後多加了一層g函數,g函數定義為:$g(z)=\frac { 1 }{ 1+{ e }^{ -Z } } $,又叫做「Sigmoid function」或是「Logistic function」。
因為將這個邏輯函數應用在線性回歸的基礎上,所以叫做邏輯回歸。Sigmoid function與Logistic function算是同義詞,所以兩者皆可代表此函數。
現在,${ h }_{ \theta }(x)$ = $g({ \theta }^{ T }x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } }$
當Z為負無限大時,g(Z)會逼近於0,當Z為正無限大時,g(Z)會逼近於1。因為g(Z)輸出的值介於0和1之間,${ h }_{ \theta }(x)$輸出的值也就介於0和1之間了。
最終,給定假設函數:${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $,我們要做的事就如同過去,為我們的data找出參數$\theta$。
另外,如果用機率角度解釋,假設函數${ h }_{ \theta }(x)$的輸出結果就是「y=1的機率」。
若現在要對一個病人的腫瘤進行預測(分類),而每個病人只有腫瘤大小這一個特徵,同樣的,還是額外定義一個x0=1,則特徵向量x為:
$x = \begin{bmatrix} { x }_{ 0 } \\ { x }_{ 1 } \end{bmatrix} = \begin{bmatrix} 1 \\ 腫瘤大小 \end{bmatrix}$
此時若${ h }_{ \theta }(x)$=0.7,就代表y=1的機率為70%,也就是其腫瘤有70%的機會會是惡性的。
以上式子還可以改寫成:${ h }_{ \theta }(x)$ = P(y=1 | x ; $\theta$)
意思是,給定每個病人其獨特的特徵向量x以及參數$\theta$時,y=1的機率(反正就是y=1的機率)。
所以給定${ h }_{ \theta }(x)$,我們也可以計算y=0的機率。由於y只會是1或0,我們知道y=0的機率加上y=1的機率會是1,也就是:P(y=1 | x ; $\theta$)+P(y=0 | x ; $\theta$)=1。所以,y=0的機率就是:P(y=0 | x ; $\theta$)=1 - P(y=1 | x ; $\theta$),簡單吧。
總之,假設函數在邏輯回歸中所代表的意思就是「輸出等於1的機率」的意思。
${ h }_{ \theta }(x) = g({ \theta }^{ T }x)$
g(Z)=$\frac { 1 }{ 1+{ e }^{ -Z } } $
前一段我們設定的決策邊界為:
當${ h }_{ \theta }(x) = g({ \theta }^{ T }x)\ge 0.5$,也就是${ \theta }^{ T }x\ge 0$時,就預測y=1。
當${ h }_{ \theta }(x) = g({ \theta }^{ T }x)<0.5$,也就是${ \theta }^{ T }x<0$時,就預測y=0。
假設現在有兩個特徵,則假設函數${ h }_{ \theta }(x)$ = $g({ \theta }_{ 0 }+{ \theta }_{ 1 }{ x }_{ 1 }+{ \theta }_{ 2 }{ x }_{ 2 })$,再另${ \theta }_{ 0 }$ = -3,${ \theta }_{ 1 }$ = 1,${ \theta }_{ 2 }$ = 1,則參數向量$\theta$為:
$\theta \quad =\quad \begin{bmatrix} -3 \\ 1 \\ 1 \end{bmatrix}$
按照之前的式子,如果${ \theta }^{ T }x$ = -3+${ x }_{ 1 }$+${ x }_{ 2 }\ge 0$,或是${ x }_{ 1 }$+${ x }_{ 2 }\ge 3$,則預測y=1。
回歸線${ x }_{ 1 }$+${ x }_{ 2 }$=3(也就是${ h }_{ \theta }(x)$=0.5)如下圖所示:

若${ x }_{ 1 }$+${ x }_{ 2 }>3$,對於落在右上那塊的data,${ h }_{ \theta }(x)$會預測y=1。反之,若${ x }_{ 1 }$+${ x }_{ 2 }<3$,對於落在左下那塊的data,${ h }_{ \theta }(x)$會預測y=0。
要注意的是,圖中這條決策邊界是由假設函數${ h }_{ \theta }(x)$ = $g({ \theta }_{ 0 }+{ \theta }_{ 1 }{ x }_{ 1 }+{ \theta }_{ 2 }{ x }_{ 2 })$所形成的,而非由圖中的data set所形成,畫出data set只是為了視覺化,如果拿掉這個data set,這條邊界依然是畫成這樣,不可倒果為因!
簡而言之,當決定出${ \theta }_{ 0 }$、${ \theta }_{ 1 }$與${ \theta }_{ 2 }$之後,這條決策邊界就已經形成了,之後才去探討data落在哪一區塊,而不是先有data才有這條決策邊界。

此圖中,這條決策邊界是怎麼畫出來的呢?在多項式回歸或是線性回歸中,我們提到可以在特徵中加入額外的「高階多項式」項目,在邏輯回歸中一樣可以這麼做。
同樣的,考慮假設函數:${ h }_{ \theta }(x)$=$g({ \theta }_{ 0 }+{ \theta }_{ 1 }{ x }_{ 1 }+{ \theta }_{ 2 }{ x }_{ 2 }+{ \theta }_{ 3 }{ x }_{ 1 }^{ 2 }+{ \theta }_{ 4 }{ x }_{ 2 }^{ 2 })$,我們加入兩個額外的特徵${ x }_{ 1 }^{ 2 }$與${ x }_{ 2 }^{ 2 }$。
下一段,我們會探討如何自動取得參數${ \theta }_{ 0 }$到${ \theta }_{ 4 }$,但此時我們先假設${ \theta }_{ 0 }=-1$,${ \theta }_{ 1 }=0$,${ \theta }_{ 2 }=0$,${ \theta }_{ 3 }=1$,${ \theta }_{ 4 }=1$。
這些參數寫成參數向量$\theta$就是:$\theta =\begin{bmatrix} -1 \\ 0 \\ 0 \\ 1 \\ 1 \end{bmatrix}$
此時就代表,如果$-1+{ x }_{ 1 }^{ 2 }+{ x }_{ 2 }^{ 2 }\ge 0$或是${ x }_{ 1 }^{ 2 }+{ x }_{ 2 }^{ 2 }\ge 1$,則預測y=1,而${ x }_{ 1 }^{ 2 }+{ x }_{ 2 }^{ 2 }=1$這條決策邊界就會長得像上圖那樣一個依照半徑為1所畫的圓。如果data落在圓圈外圍,將會預測y=1。
因此,當加入額外的多項式項目到我的特徵後,就可以得到長得更複雜的決策邊界,而不單單只是由一條 直線來分類而已。同樣的,決策邊界是由參數向量$\theta $所形成的,而非由data set所形成。
總之,當你加入越多的多項式項目到特徵中,你的決策邊界也會越複雜或奇特,下一段我們會探討如何自動化取得參數$\theta$的值並應用在我們的data中。
$x\in \begin{bmatrix} { x }_{ 0 } \\ { x }_{ 1 } \\ ... \\ { x }_{ n } \end{bmatrix}$,其中${ x }_{ 0 }$=1,y={0,1}
${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $
給定這個training set,我們該如何找出參數$\theta$?
在線性回歸中:成本函數$J(\theta )=\frac { 1 }{ m } \sum _{ i=1 }^{ m }{ \frac { 1 }{ 2 } } { ({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) }^{ 2 }$,這邊我們把1/2寫進求和裡面。其中我們將$\frac { 1 }{ 2 } { ({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) }^{ 2 }$看成$Cost{ ({ h }_{ \theta }({ x }^{ (i) }),{ y }^{ (i) }) }$。
若再簡化一下,不要寫(i),則$Cost{ ({ h }_{ \theta }({ x }),{ y }) }$=$\frac { 1 }{ 2 } { ({ h }_{ \theta }({ x })-{ y }) }^{ 2 }$。
討論線性回歸時提過,成本函數的意思就是輸出${ h }_{ \theta }({ x })的值$,所必須付出的成本,這個函數用在線性回歸是可以的,但是用在邏輯回歸會變成一個non-convex function(非凸集函數)。
以下是我對non-convex的解釋:
由於${ h }_{ \theta }(x)$ = $g({ \theta }^{ T }x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $,其中g函數(也就是Sigmoid函數)是一個非常不線性的函數,如果套用在成本函數$J(\theta )$,則$J(\theta )$可能會長成如下左圖所示,有很多局部最小值,一個比較正式的稱呼是非凸函數。

如果你把梯度下降法用在這樣一個成本函數上,你無法保證梯度下降法能夠收斂到該函數的全局最小值。相反的,凸函數則如右圖所示,把梯度下降法用在上面,可以保證梯度下降法會收斂到該函數的全局最小值。
所以,如果你將Sigmoid函數帶進平方誤差成本函數,會使其變成一個非凸函數。我們現在要做的,就是找出可以保證使用梯度下降法會收斂到該函數的全局最小值的另一個替代的成本函數。
以下是邏輯回歸應該使用的成本函數:
$Cost({ h }_{ \theta }(x),y)=\begin{cases} -log({ h }_{ \theta }(x))\quad \quad if\quad y=1 \\ -log(1-{ h }_{ \theta }(x))\quad if\quad y=0 \end{cases}$
將y=1的case畫成圖如下,其中${ h }_{ \theta }(x)$介於0~1之間:

為何y=1的圖為何會這樣畫,可以這樣理解,Z現在代表${ h }_{ \theta }(x)$,當橫軸叫做Z軸時,-log(Z)會呈現如下圖紅色曲線:

由於我們感興趣的只有何時成本函數才會產生0~1的值,所以我們把紫色框那個0~1的區間獨立出來,這就是y=1那張 圖的由來。
這個成本函數有些有趣的特性,首先,如果y確實等於1,且假設函數${ h }_{ \theta }(x)$的輸出也等於1,則Cost=0,因為我們確實正確的預測出了y=1,成本當然就是0。
但如果假設函數${ h }_{ \theta }(x)$的輸出逼近於0時,成本會接近無限大。這很直覺,如果${ h }_{ \theta }(x)$=0,也可以說P(y=1|x;$\theta$)=0,也就是y=1的機率為0,用在腫瘤例子就是我們預測腫瘤會是惡性的機率為0,但事實上腫瘤是惡性的,因為現在y是等於1,所以我們這個學習演算法其實判斷錯誤了,付出的成本當然就很高。如果y=0,以上狀況就反之囉(看下圖)。
這是我們完整的成本函數:$J(\theta )=\frac { 1 }{ m } \sum _{ i=1 }^{ m }Cost{ ({ h }_{ \theta }({ x }^{ (i) }),{ y }^{ (i) }) }$
其中$Cost({ h }_{ \theta }(x),y)=\begin{cases} \quad -log({ h }_{ \theta }(x))\quad if\quad y=1 \\ -log(1-{ h }_{ \theta }(x))\quad if\quad y=0 \end{cases}$
${ h }_{ \theta }(x)$對實際值${ y }^{ (i) }$進行預測後,之間的差異就是單個樣本的成本值,加總所有這些差異後就是這個成本函數的輸出。
在分類問題中,我們的training set或是其他不在我們training set的樣本,y的值永遠都是1或是0,這是y的數學定義決定的。
由於y要嘛是0要嘛是1,我們就可以用一個簡單方式來寫這個成本函數,為了讓這個函數不要分成y=1與y=0這兩種狀況,我們可以將它寫成一個式子就好。這樣可以簡易的寫出成本函數並推導出梯度下降法。
$ Cost({ h }_{ \theta }(x),y) = - y log({ h }_{ \theta }(x))\quad +\quad - (1-y) log(1-{ h }_{ \theta }(x))$
如果y=1,$Cost({ h }_{ \theta }(x),y) = -log({ h }_{ \theta }(x))$
如果y=0,$Cost({ h }_{ \theta }(x),y) = -log(1-{ h }_{ \theta }(x))$
因此以下我們可以導出最終的邏輯回歸的成本函數:
$J(\theta )=\frac { 1 }{ m } \sum _{ i=1 }^{ m }Cost{ ({ h }_{ \theta }({ x }^{ (i) }),{ y }^{ (i) }) }$
$=-\frac { 1 }{ m }[\sum _{ i=1 }^{ m }{ { y }^{ (i) }log{ h }_{ \theta }({ x }^{ (i) })\quad +\quad (1-{ y }^{ (i) })log(1-{ h }_{ \theta }({ x }^{ (i) })) } ]$
以上就是這個式子大家最常用的寫法,至於為何會有這種寫法呢?主要是來自統計學的maximum likelihood estimation(MLE)。
至於要怎麼找參數$\theta$呢?我們得試圖找出能夠讓J($\theta$)的輸出儘量最小值的參數$\theta$:${ min }_{ \theta }$ J($\theta$),也就是最小化J($\theta$)。
J($\theta$)會輸出一群參數$\theta$,例如$\Theta =\begin{bmatrix} { \theta }_{ 0 } \\ { \theta }_{ 1 } \\ { \theta }_{ 2 } \\ ... \\ { \theta }_{ n } \end{bmatrix}$。
如果有一個新的example,其有一群特徵寫成特徵向量x,我們要對它進行預測時,就可以將${ min }_{ \theta }$ J($\theta$)所輸出的這群$\theta$用在我們的training set,讓${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $進行假設預測,而我們的假設其實就是預測y=1的機率(就是P(y=1|x;$\theta$))。
接下來的工作就是要知道如何最小化成本函數J($\theta$),也就是為training set找出最理想的參數$\theta$。最小化成本函數的方法就是使用梯度下降法,以下是常用的梯度下降法的模板,我們用這個式子反覆更新每個參數:
Repeat{
${ \theta }_{ j }:={ \theta }_{ j }-\alpha \frac { \partial }{ \partial { \theta }_{ j } } J(\theta )$
}
${ \theta }_{ j }$自己減去學習速率$\alpha$乘以後面的微分項,最後就會變成如下這樣:
Repeat{
${ \theta }_{ j }:={ \theta }_{ j }-\alpha \sum _{ i=1 }^{ m }{ ({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) } { x }_{ j }^{ (i) }$
}
如果你有n個特徵,也就是說參數向量$\Theta =\begin{bmatrix} { \theta }_{ 0 } \\ { \theta }_{ 1 } \\ { \theta }_{ 2 } \\ ... \\ { \theta }_{ n } \end{bmatrix}$,此時你就可以用以上式子來同時更新所有$\theta$的值。
最後,你會發現這個更新參數的式子跟線性回歸時的梯度下降式子是相同的。那麼線性回歸跟邏輯回歸兩者的規則有差嗎?有的,實際上,假設的定義有發生了變化:
在線性回歸中,我們是假設${ h }_{ \theta }(x)$ = ${ \theta }^{ T }x$
在邏輯回歸中,我們是假設${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } }$
所以兩者的梯度下降法實際上是兩個完全不同的東西。當我們在談論線性回歸的梯度下降法時,我們談到了如何監控梯度下降法以確保其收斂,而在邏輯回歸中也可以使用同樣的方法。在更新參數時可以用一個for迴圈(for j in range(0,n):)來更新,但更理想的是,我們可以使用向量化的實現(vectorized implementation)來同時更新參數,也就是:
${ \theta }:={ \theta }-\alpha \frac { 1 }{ m } \sum _{ i=1 }^{ m }{ [({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) } { x }^{ (i) }]$
最後,線性回歸所講到的特徵縮放(Feature scaling)也可以用在邏輯回歸中,如果你的特徵彼此之間差距很大的話,將特徵縮放用在邏輯回歸也可以讓梯度下降法收斂得更快。

寫程式時,可能需要寫$J(\theta)$以及$\frac { \partial }{ \partial { \theta }_{ j } } J(\theta )$的code,寫完後就可以使用梯度下降法。其實不只有梯度下降法可以使用,最佳化演算法有如下可以選擇:
除了梯度下降法,其他三個都超出本課程範圍,不過它們有些好處,首先它們不需要手動選擇學習速率$\alpha$且收斂速度通常都比梯度下降法快,缺點就是更複雜了點。除非你是數值計算專家,否則儘量不要用這些方法,且儘量不要自己寫這些演算法,因為效能好與不好是很明顯的,直接用專家寫好的library比較適合。
舉個例子,假設現在有兩個特徵,也就是有兩個參數${ \theta }_{ 1 }$與${ \theta }_{ 2 }$,若你想要最小化J(\theta),則${ \theta }_{ 1 }=5$且${ \theta }_{ 2 }=5$,以下為octave的code:

如果把它應用到邏輯回歸呢?如下所示:

主要就是希望你寫一個可以返回成本函數值以及梯度值的函數,此演算法也可以用在線性回歸。如果你要用到非常高級的機器學習,就要使用這些比較進階的演算法,而不是梯度下降法。
又如果有一個病人因為鼻子不舒服來看診,則他的陣狀可能有:沒生病(y=1)、著涼(y=2)、流感(y=3)
最後一個例子,如果你遇到一個有關天氣的機器學習分類問題,則天氣可能有晴天(y=1)、多雲(y=2)、雨天(y=3)、下雪(y=4)。
y寫成0,1,2,3或是1,2,3,4都沒關係,不會影響最後結果。
以下為二元分類問題與多元(三元)分類問題的比較,三元分類問題總共有三個類別:

以下講解one-vs-all演算法,one-vs-all又可叫作one-vs-rest。對於三元分類問題,我們要做的就是將我們的training set分成「三個二元分類問題」,對於類別1,我們建立一個新的偽training set充當類別2與類別3。類別1(三角形)代表正樣本(值=1),偽類別2,3(圓形)代表負樣本(值=0),之後就可以找出合適的邏輯回歸分類器分開正副樣本,對於類別2與3,方法一樣:
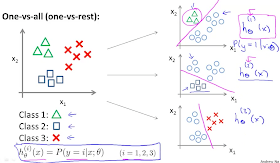
最後,我們擬合出了三個分類器,i=1,2,3,每個分類器都對其中一種狀況進行訓練。

對於每個新的輸入x,我們選擇一個能讓分類器${ h }_{ \theta }^{ (i) }$最大化的類別i,當作是x屬於的類別,也就是選出哪個分類器的效果最好,我們就認為得到最好的分類。有了一對多這個演算法,你就可以把邏輯回歸用於多元分類問題了。
邏輯回歸的假設函數
現在來談談Logistic regression,Logistic regression模型想要讓0$\le { h }_{ \theta }(x)\le$1,原本Linear regression的輸出為${ h }_{ \theta }(x)$ = ${ \theta }^{ T }x$,現在Logistic regression的輸出則變成了:${ h }_{ \theta }(x)$ = $g({ \theta }^{ T }x)$簡單說,就是以線性回歸為基礎,在最後多加了一層g函數,g函數定義為:$g(z)=\frac { 1 }{ 1+{ e }^{ -Z } } $,又叫做「Sigmoid function」或是「Logistic function」。
因為將這個邏輯函數應用在線性回歸的基礎上,所以叫做邏輯回歸。Sigmoid function與Logistic function算是同義詞,所以兩者皆可代表此函數。
現在,${ h }_{ \theta }(x)$ = $g({ \theta }^{ T }x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } }$
當Z為負無限大時,g(Z)會逼近於0,當Z為正無限大時,g(Z)會逼近於1。因為g(Z)輸出的值介於0和1之間,${ h }_{ \theta }(x)$輸出的值也就介於0和1之間了。
最終,給定假設函數:${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $,我們要做的事就如同過去,為我們的data找出參數$\theta$。
另外,如果用機率角度解釋,假設函數${ h }_{ \theta }(x)$的輸出結果就是「y=1的機率」。
若現在要對一個病人的腫瘤進行預測(分類),而每個病人只有腫瘤大小這一個特徵,同樣的,還是額外定義一個x0=1,則特徵向量x為:
$x = \begin{bmatrix} { x }_{ 0 } \\ { x }_{ 1 } \end{bmatrix} = \begin{bmatrix} 1 \\ 腫瘤大小 \end{bmatrix}$
此時若${ h }_{ \theta }(x)$=0.7,就代表y=1的機率為70%,也就是其腫瘤有70%的機會會是惡性的。
以上式子還可以改寫成:${ h }_{ \theta }(x)$ = P(y=1 | x ; $\theta$)
意思是,給定每個病人其獨特的特徵向量x以及參數$\theta$時,y=1的機率(反正就是y=1的機率)。
所以給定${ h }_{ \theta }(x)$,我們也可以計算y=0的機率。由於y只會是1或0,我們知道y=0的機率加上y=1的機率會是1,也就是:P(y=1 | x ; $\theta$)+P(y=0 | x ; $\theta$)=1。所以,y=0的機率就是:P(y=0 | x ; $\theta$)=1 - P(y=1 | x ; $\theta$),簡單吧。
總之,假設函數在邏輯回歸中所代表的意思就是「輸出等於1的機率」的意思。
線性的決策邊界(Decision boundary)
回顧一下:${ h }_{ \theta }(x) = g({ \theta }^{ T }x)$
g(Z)=$\frac { 1 }{ 1+{ e }^{ -Z } } $
前一段我們設定的決策邊界為:
當${ h }_{ \theta }(x) = g({ \theta }^{ T }x)\ge 0.5$,也就是${ \theta }^{ T }x\ge 0$時,就預測y=1。
當${ h }_{ \theta }(x) = g({ \theta }^{ T }x)<0.5$,也就是${ \theta }^{ T }x<0$時,就預測y=0。
$\theta \quad =\quad \begin{bmatrix} -3 \\ 1 \\ 1 \end{bmatrix}$
按照之前的式子,如果${ \theta }^{ T }x$ = -3+${ x }_{ 1 }$+${ x }_{ 2 }\ge 0$,或是${ x }_{ 1 }$+${ x }_{ 2 }\ge 3$,則預測y=1。
回歸線${ x }_{ 1 }$+${ x }_{ 2 }$=3(也就是${ h }_{ \theta }(x)$=0.5)如下圖所示:
若${ x }_{ 1 }$+${ x }_{ 2 }>3$,對於落在右上那塊的data,${ h }_{ \theta }(x)$會預測y=1。反之,若${ x }_{ 1 }$+${ x }_{ 2 }<3$,對於落在左下那塊的data,${ h }_{ \theta }(x)$會預測y=0。
要注意的是,圖中這條決策邊界是由假設函數${ h }_{ \theta }(x)$ = $g({ \theta }_{ 0 }+{ \theta }_{ 1 }{ x }_{ 1 }+{ \theta }_{ 2 }{ x }_{ 2 })$所形成的,而非由圖中的data set所形成,畫出data set只是為了視覺化,如果拿掉這個data set,這條邊界依然是畫成這樣,不可倒果為因!
簡而言之,當決定出${ \theta }_{ 0 }$、${ \theta }_{ 1 }$與${ \theta }_{ 2 }$之後,這條決策邊界就已經形成了,之後才去探討data落在哪一區塊,而不是先有data才有這條決策邊界。
非線性的決策邊界(Decision boundary)
此圖中,這條決策邊界是怎麼畫出來的呢?在多項式回歸或是線性回歸中,我們提到可以在特徵中加入額外的「高階多項式」項目,在邏輯回歸中一樣可以這麼做。
同樣的,考慮假設函數:${ h }_{ \theta }(x)$=$g({ \theta }_{ 0 }+{ \theta }_{ 1 }{ x }_{ 1 }+{ \theta }_{ 2 }{ x }_{ 2 }+{ \theta }_{ 3 }{ x }_{ 1 }^{ 2 }+{ \theta }_{ 4 }{ x }_{ 2 }^{ 2 })$,我們加入兩個額外的特徵${ x }_{ 1 }^{ 2 }$與${ x }_{ 2 }^{ 2 }$。
下一段,我們會探討如何自動取得參數${ \theta }_{ 0 }$到${ \theta }_{ 4 }$,但此時我們先假設${ \theta }_{ 0 }=-1$,${ \theta }_{ 1 }=0$,${ \theta }_{ 2 }=0$,${ \theta }_{ 3 }=1$,${ \theta }_{ 4 }=1$。
這些參數寫成參數向量$\theta$就是:$\theta =\begin{bmatrix} -1 \\ 0 \\ 0 \\ 1 \\ 1 \end{bmatrix}$
此時就代表,如果$-1+{ x }_{ 1 }^{ 2 }+{ x }_{ 2 }^{ 2 }\ge 0$或是${ x }_{ 1 }^{ 2 }+{ x }_{ 2 }^{ 2 }\ge 1$,則預測y=1,而${ x }_{ 1 }^{ 2 }+{ x }_{ 2 }^{ 2 }=1$這條決策邊界就會長得像上圖那樣一個依照半徑為1所畫的圓。如果data落在圓圈外圍,將會預測y=1。
因此,當加入額外的多項式項目到我的特徵後,就可以得到長得更複雜的決策邊界,而不單單只是由一條 直線來分類而已。同樣的,決策邊界是由參數向量$\theta $所形成的,而非由data set所形成。
總之,當你加入越多的多項式項目到特徵中,你的決策邊界也會越複雜或奇特,下一段我們會探討如何自動化取得參數$\theta$的值並應用在我們的data中。
邏輯回歸的成本函數
假設我們有一個具有m個examples的training set,特徵向量以及假設函數如下,$x\in \begin{bmatrix} { x }_{ 0 } \\ { x }_{ 1 } \\ ... \\ { x }_{ n } \end{bmatrix}$,其中${ x }_{ 0 }$=1,y={0,1}
${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $
給定這個training set,我們該如何找出參數$\theta$?
在線性回歸中:成本函數$J(\theta )=\frac { 1 }{ m } \sum _{ i=1 }^{ m }{ \frac { 1 }{ 2 } } { ({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) }^{ 2 }$,這邊我們把1/2寫進求和裡面。其中我們將$\frac { 1 }{ 2 } { ({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) }^{ 2 }$看成$Cost{ ({ h }_{ \theta }({ x }^{ (i) }),{ y }^{ (i) }) }$。
若再簡化一下,不要寫(i),則$Cost{ ({ h }_{ \theta }({ x }),{ y }) }$=$\frac { 1 }{ 2 } { ({ h }_{ \theta }({ x })-{ y }) }^{ 2 }$。
討論線性回歸時提過,成本函數的意思就是輸出${ h }_{ \theta }({ x })的值$,所必須付出的成本,這個函數用在線性回歸是可以的,但是用在邏輯回歸會變成一個non-convex function(非凸集函數)。
以下是我對non-convex的解釋:
由於${ h }_{ \theta }(x)$ = $g({ \theta }^{ T }x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $,其中g函數(也就是Sigmoid函數)是一個非常不線性的函數,如果套用在成本函數$J(\theta )$,則$J(\theta )$可能會長成如下左圖所示,有很多局部最小值,一個比較正式的稱呼是非凸函數。

如果你把梯度下降法用在這樣一個成本函數上,你無法保證梯度下降法能夠收斂到該函數的全局最小值。相反的,凸函數則如右圖所示,把梯度下降法用在上面,可以保證梯度下降法會收斂到該函數的全局最小值。
所以,如果你將Sigmoid函數帶進平方誤差成本函數,會使其變成一個非凸函數。我們現在要做的,就是找出可以保證使用梯度下降法會收斂到該函數的全局最小值的另一個替代的成本函數。
以下是邏輯回歸應該使用的成本函數:
$Cost({ h }_{ \theta }(x),y)=\begin{cases} -log({ h }_{ \theta }(x))\quad \quad if\quad y=1 \\ -log(1-{ h }_{ \theta }(x))\quad if\quad y=0 \end{cases}$
將y=1的case畫成圖如下,其中${ h }_{ \theta }(x)$介於0~1之間:
為何y=1的圖為何會這樣畫,可以這樣理解,Z現在代表${ h }_{ \theta }(x)$,當橫軸叫做Z軸時,-log(Z)會呈現如下圖紅色曲線:
由於我們感興趣的只有何時成本函數才會產生0~1的值,所以我們把紫色框那個0~1的區間獨立出來,這就是y=1那張 圖的由來。
這個成本函數有些有趣的特性,首先,如果y確實等於1,且假設函數${ h }_{ \theta }(x)$的輸出也等於1,則Cost=0,因為我們確實正確的預測出了y=1,成本當然就是0。
但如果假設函數${ h }_{ \theta }(x)$的輸出逼近於0時,成本會接近無限大。這很直覺,如果${ h }_{ \theta }(x)$=0,也可以說P(y=1|x;$\theta$)=0,也就是y=1的機率為0,用在腫瘤例子就是我們預測腫瘤會是惡性的機率為0,但事實上腫瘤是惡性的,因為現在y是等於1,所以我們這個學習演算法其實判斷錯誤了,付出的成本當然就很高。如果y=0,以上狀況就反之囉(看下圖)。


簡化成本函數以及梯度下降法
這一段我們會探討如何簡化成本函數的寫法,以及如何利用梯度下降法來選出理想的邏輯回歸的參數$\theta$,講完這一段你就可以知道如何實現一個完整的邏輯回歸演算法了。這是我們完整的成本函數:$J(\theta )=\frac { 1 }{ m } \sum _{ i=1 }^{ m }Cost{ ({ h }_{ \theta }({ x }^{ (i) }),{ y }^{ (i) }) }$
其中$Cost({ h }_{ \theta }(x),y)=\begin{cases} \quad -log({ h }_{ \theta }(x))\quad if\quad y=1 \\ -log(1-{ h }_{ \theta }(x))\quad if\quad y=0 \end{cases}$
${ h }_{ \theta }(x)$對實際值${ y }^{ (i) }$進行預測後,之間的差異就是單個樣本的成本值,加總所有這些差異後就是這個成本函數的輸出。
在分類問題中,我們的training set或是其他不在我們training set的樣本,y的值永遠都是1或是0,這是y的數學定義決定的。
由於y要嘛是0要嘛是1,我們就可以用一個簡單方式來寫這個成本函數,為了讓這個函數不要分成y=1與y=0這兩種狀況,我們可以將它寫成一個式子就好。這樣可以簡易的寫出成本函數並推導出梯度下降法。
$ Cost({ h }_{ \theta }(x),y) = - y log({ h }_{ \theta }(x))\quad +\quad - (1-y) log(1-{ h }_{ \theta }(x))$
如果y=1,$Cost({ h }_{ \theta }(x),y) = -log({ h }_{ \theta }(x))$
如果y=0,$Cost({ h }_{ \theta }(x),y) = -log(1-{ h }_{ \theta }(x))$
因此以下我們可以導出最終的邏輯回歸的成本函數:
$J(\theta )=\frac { 1 }{ m } \sum _{ i=1 }^{ m }Cost{ ({ h }_{ \theta }({ x }^{ (i) }),{ y }^{ (i) }) }$
$=-\frac { 1 }{ m }[\sum _{ i=1 }^{ m }{ { y }^{ (i) }log{ h }_{ \theta }({ x }^{ (i) })\quad +\quad (1-{ y }^{ (i) })log(1-{ h }_{ \theta }({ x }^{ (i) })) } ]$
以上就是這個式子大家最常用的寫法,至於為何會有這種寫法呢?主要是來自統計學的maximum likelihood estimation(MLE)。
至於要怎麼找參數$\theta$呢?我們得試圖找出能夠讓J($\theta$)的輸出儘量最小值的參數$\theta$:${ min }_{ \theta }$ J($\theta$),也就是最小化J($\theta$)。
J($\theta$)會輸出一群參數$\theta$,例如$\Theta =\begin{bmatrix} { \theta }_{ 0 } \\ { \theta }_{ 1 } \\ { \theta }_{ 2 } \\ ... \\ { \theta }_{ n } \end{bmatrix}$。
如果有一個新的example,其有一群特徵寫成特徵向量x,我們要對它進行預測時,就可以將${ min }_{ \theta }$ J($\theta$)所輸出的這群$\theta$用在我們的training set,讓${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } } $進行假設預測,而我們的假設其實就是預測y=1的機率(就是P(y=1|x;$\theta$))。
接下來的工作就是要知道如何最小化成本函數J($\theta$),也就是為training set找出最理想的參數$\theta$。最小化成本函數的方法就是使用梯度下降法,以下是常用的梯度下降法的模板,我們用這個式子反覆更新每個參數:
Repeat{
${ \theta }_{ j }:={ \theta }_{ j }-\alpha \frac { \partial }{ \partial { \theta }_{ j } } J(\theta )$
}
${ \theta }_{ j }$自己減去學習速率$\alpha$乘以後面的微分項,最後就會變成如下這樣:
Repeat{
${ \theta }_{ j }:={ \theta }_{ j }-\alpha \sum _{ i=1 }^{ m }{ ({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) } { x }_{ j }^{ (i) }$
}
如果你有n個特徵,也就是說參數向量$\Theta =\begin{bmatrix} { \theta }_{ 0 } \\ { \theta }_{ 1 } \\ { \theta }_{ 2 } \\ ... \\ { \theta }_{ n } \end{bmatrix}$,此時你就可以用以上式子來同時更新所有$\theta$的值。
最後,你會發現這個更新參數的式子跟線性回歸時的梯度下降式子是相同的。那麼線性回歸跟邏輯回歸兩者的規則有差嗎?有的,實際上,假設的定義有發生了變化:
在線性回歸中,我們是假設${ h }_{ \theta }(x)$ = ${ \theta }^{ T }x$
在邏輯回歸中,我們是假設${ h }_{ \theta }(x)$ = $\frac { 1 }{ 1+{ e }^{ -{ \theta }^{ T }x } }$
所以兩者的梯度下降法實際上是兩個完全不同的東西。當我們在談論線性回歸的梯度下降法時,我們談到了如何監控梯度下降法以確保其收斂,而在邏輯回歸中也可以使用同樣的方法。在更新參數時可以用一個for迴圈(for j in range(0,n):)來更新,但更理想的是,我們可以使用向量化的實現(vectorized implementation)來同時更新參數,也就是:
${ \theta }:={ \theta }-\alpha \frac { 1 }{ m } \sum _{ i=1 }^{ m }{ [({ h }_{ \theta }({ x }^{ (i) })-{ y }^{ (i) }) } { x }^{ (i) }]$
最後,線性回歸所講到的特徵縮放(Feature scaling)也可以用在邏輯回歸中,如果你的特徵彼此之間差距很大的話,將特徵縮放用在邏輯回歸也可以讓梯度下降法收斂得更快。
最佳化演算法

寫程式時,可能需要寫$J(\theta)$以及$\frac { \partial }{ \partial { \theta }_{ j } } J(\theta )$的code,寫完後就可以使用梯度下降法。其實不只有梯度下降法可以使用,最佳化演算法有如下可以選擇:
- Gradient descent
- Conjugate gradient
- BFGS
- L-BFGS
除了梯度下降法,其他三個都超出本課程範圍,不過它們有些好處,首先它們不需要手動選擇學習速率$\alpha$且收斂速度通常都比梯度下降法快,缺點就是更複雜了點。除非你是數值計算專家,否則儘量不要用這些方法,且儘量不要自己寫這些演算法,因為效能好與不好是很明顯的,直接用專家寫好的library比較適合。
舉個例子,假設現在有兩個特徵,也就是有兩個參數${ \theta }_{ 1 }$與${ \theta }_{ 2 }$,若你想要最小化J(\theta),則${ \theta }_{ 1 }=5$且${ \theta }_{ 2 }=5$,以下為octave的code:

如果把它應用到邏輯回歸呢?如下所示:

主要就是希望你寫一個可以返回成本函數值以及梯度值的函數,此演算法也可以用在線性回歸。如果你要用到非常高級的機器學習,就要使用這些比較進階的演算法,而不是梯度下降法。
多類別分類問題(one-vs-all classification algorithm)
假設你現在希望有一個演算法可以自動將郵件分類,或者說自動加上標籤,則你可能會有很多種郵件資料夾,例如工作(y=1)、朋友(y=2)、家庭(y=3)、興趣(y=4)等四類。又如果有一個病人因為鼻子不舒服來看診,則他的陣狀可能有:沒生病(y=1)、著涼(y=2)、流感(y=3)
最後一個例子,如果你遇到一個有關天氣的機器學習分類問題,則天氣可能有晴天(y=1)、多雲(y=2)、雨天(y=3)、下雪(y=4)。
y寫成0,1,2,3或是1,2,3,4都沒關係,不會影響最後結果。
以下為二元分類問題與多元(三元)分類問題的比較,三元分類問題總共有三個類別:

以下講解one-vs-all演算法,one-vs-all又可叫作one-vs-rest。對於三元分類問題,我們要做的就是將我們的training set分成「三個二元分類問題」,對於類別1,我們建立一個新的偽training set充當類別2與類別3。類別1(三角形)代表正樣本(值=1),偽類別2,3(圓形)代表負樣本(值=0),之後就可以找出合適的邏輯回歸分類器分開正副樣本,對於類別2與3,方法一樣:

最後,我們擬合出了三個分類器,i=1,2,3,每個分類器都對其中一種狀況進行訓練。

對於每個新的輸入x,我們選擇一個能讓分類器${ h }_{ \theta }^{ (i) }$最大化的類別i,當作是x屬於的類別,也就是選出哪個分類器的效果最好,我們就認為得到最好的分類。有了一對多這個演算法,你就可以把邏輯回歸用於多元分類問題了。